关于引用
前几天面试被问了关于引用的一些问题,来总结一下
对于引用 我对他的印象就只是那句烂大街的 “引用是变量的一个别名”
左值和右值
左值:在内存有确定存储地址、有变量名,表达式结束依然存在的值,简单来说左值就是非临时对象
右值:就是在内存没有确定存储地址、没有变量名,表达式结束就会销毁的值,简单来说右值就是临时对象
1 | |
x++ 中, 编译器会先对x复制,然后x自增,最后返回复制的x, 所以这里 x++ 本身是一个右值 因为返回的并不是x,而是先前复制的x的值
++x对x自增后马上返回其自身,所以为一个左值
编译器会将字符串的字面量存储到程序的数据段中,程序加载时也会为其开辟空间,所以可以取址
左值和右值的区别
左值持久,右值短暂
左值一定在内存中,右值有可能在内存中也有可能在寄存器中
左值可以寻址,而右值不可以
左值可以被赋值,右值不可以被赋值,可以用来给左值赋值
左值可变,右值不可变(仅对基础类型适用,用户自定义类型右值引用可以通过成员函数改变)
左值引用
绑定到左值的引用,通过&来获得左值引用
左值引用实际上是一种隐式的指针,它为对象建立一个别名,通过操作符&来实现
左值引用的出现让c++在一定程度上脱离了危险的指针
非常量左值只能引用非常量左值
常量左值可以引用所有类型(所有左值和右值)
1 | |
1 | |
这两段代码从结果上来说好像差别不大
但从语法上来说,后者的11 的生命周期会被延长,前者的11 会在语结束后被销毁
虽然常量左值可以引用右值这个特点与赋值相比并无太大优势,但在函数的形参列表中有巨大作用
比如说写类
1 | |
用常量左值引用就可以减少类的拷贝开销
关于类的成员为引用的问题
类的成员可以是引用,如果不使用其他变量,引用就无法存在。因此,必须在构造函数初始化器中初始化引用数据程序,而不是在构造函数体内
1 | |
右值引用
为什么要引入右值引用
右值引用是C++11中新增加的一个很重要的特性
常量左值可以引用右值,但很难受的一点就是作为函数的参数时,无法在函数内修改其内容(强制类型转换除外)
所以就有了右值引用
右值引用
右值引用可以理解为右值的引用,当右值引用初始化后,临时变量消失
通过&&来获得右值引用
右值引用可以且只可以引用右值
非常量右值只能绑定非常量右值
常量右值可以绑定常量和非常量的右值,但不能绑定左值
1 | |
右值引用的特点:
一个右值引用被初始化后,无法使用它再去引用另一个对象,它不能被重新约束。
右值引用初始化后,具有该类型数据的所有操作。
右值引用只可以初始化右值,但右值引用实质上是一个左值,它具有临时变量的数据类型。
被引用的右值不会立即销毁,生命周期和引用变量一样长
如果不考虑const的性质,右值引用和 常量左值引用差不多
右值引用的例子
举一个栗子
T a=ReturnValue();//有一次对象的析构和构造
T&& a=ReturnValue();//直接绑定函数右值,不需要拷贝
移动语义
移动语义是基于移动构造函数和移动赋值运算符的
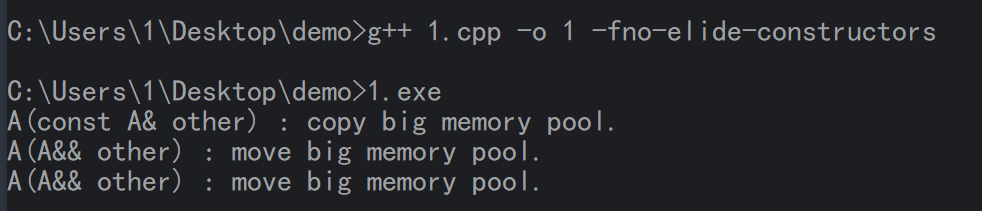
看下面程序
1 | |

关闭编译优化以后,会有3次拷贝构造:
get_A返回的临时对象
make_A返回的临时对象
main函数中调用make_A()返回的临时对象
无疑这个开销是很大的
在原来的类中加上后
1 | |
减小了开销
对于右值编译器会优先选择使用移动构造函数去构造目标对象
当移动构造函数不存在时会使用复制构造
个人感觉是一个浅拷贝,所以开销要小
移动赋值函数
1 | |
使用移动语义有很大的风险,这个风险来自于异常
如果一个对象的一部分资源移动到另一个对象,会造成两个对象都不完整的情况
move函数
右值引用不能绑定任何类型的左值,若想利用右值引用绑定左值该怎么办呢?
C++11中提供了一个标准库move函数获得绑定到左值上的右值引用,即直接调用std::move告诉编译器将左值像对待同类型右值一样处理,但是被调用后的左值将不能再被使用
move的底层是static_cast
1 | |
指针与引用
区别
指针是一种数据类型,而引用不是一个数据类型
指针可以转换为它所指向的变量的数据类型,以便赋值运算两边的类型相匹配;使用引用时,系统要求引用和变量的数据烈性必须相同,不能进行类型转换
引用不可以为空,在声明时需要初始化,且引用一旦绑定不可修改
指针不需要,而且可以指向其他数据
指针可以有多级,但引用只能是一级
sizeof 引用得到的是所指向的变量(对象)的大小,而 sizeof 指针得到的是指针变量本身的大小
指针作为函数参数传递时传递的是指针变量的值,而引用作为函数参数传递时传递的是实参本身,而不是拷贝副本
指针和引用进行++运算意义不一样
一个对象的地址可以转化成一种指定类型的指针或者一个相似类型的引用
1 | |
不要混淆取地址和引用,当&说明符前面带有类型声明,则是引用,否则就是取地址。
通俗来说 &在 ”=” 号左边的是引用,右边的是取地址
在函数传参时的区别:
需要返回函数内局部变量的内存的时候用指针,返回局部变量的引用是没有意义的
对栈空间大小比较敏感(比如递归)的时候使用引用。使用引用传递不需要创建临时变量,开销要更小
类对象作为参数传递的时候使用引用,这是C++类对象传递的标准方式
优缺点
| 优点 | 缺点 | |
|---|---|---|
| 指针 | 可以减少参数传递带来的开销, 可以随意修改指针参数指向的对象 | 需要验证指针参数是否为空指针 , 因为调用函数传递0,语句是合法的,被认为是空指针,但却也带来了隐患 |
| 引用 | 可以减少参数传递带来的开销,引用必须被初始化一个对象,并且不能使它再指向其他对象,因此对应赋值实际上是对目标对象的赋值。在函数中不需要验证引用参数的合法性 | 引用一旦初始化后,就不能修改指定的对象 |
后记
这个东西断断续续写了好久,看了很多资料,没想到一句话后面还有这么多东西 把这些资料中我可以理解的部分做了一个整合
还有一些关于引用折叠和完美转发的东西,最近实在是不想看了
等这一部分内容完全掌握之后再来补~